Introduction
AWS aims to deliver 99.99% uptime in cloud environments, using commercially reasonable efforts to achieve the availability target within each monthly billing cycle. Despite this high level of service, downtime may occur approximately 8.6 seconds per day or over one minute per week, potentially causing data loss or application disruptions. Ensuring data resilience and high availability is essential, particularly for critical applications.
The Reserve Rebuild capabilities of Hitachi Virtual Storage Platform One Software-defined Storage Block (VSP One SDS Block) enhance fault tolerance during Elastic Block Store (EBS) failures. Customers can enhance data protection and optimize storage space while maintaining performance during unexpected downtimes by selecting rebuild capacities that align with application criticality.
Selecting an appropriate rebuild policy based on application criticality enhances data protection and ensures consistent performance. For critical workloads, configuring a Fixed Rebuild Policy for two EBS drives per node increases fault tolerance by enabling the rebuild of two EBS drives. For less critical applications, a Fixed Rebuild Policy for one EBS drive per node provides sufficient protection while offering the flexibility to expand capacity for a second rebuild when required.
This blog describes the best practices for managing EBS failures and maximizing Reserve Rebuild capabilities on VSP One SDS Block in AWS. In addition, the blog provides guidance on achieving the optimal balance between resiliency and storage efficiency.
Reserve Rebuild Capacity in VSP One SDS Block
Reserve Rebuild Capacity refers to the dedicated storage resources allocated within a storage system, such as VSP One SDS Block, to handle data recovery when a failure occurs. In the context of cloud storage and AWS EBS, this capacity is reserved specifically to rebuild and restore data from a failed disk or storage component, ensuring that data integrity and system functionality are maintained. There are two types of Reserve Rebuild Capacity supported in VSP One SDS Block.
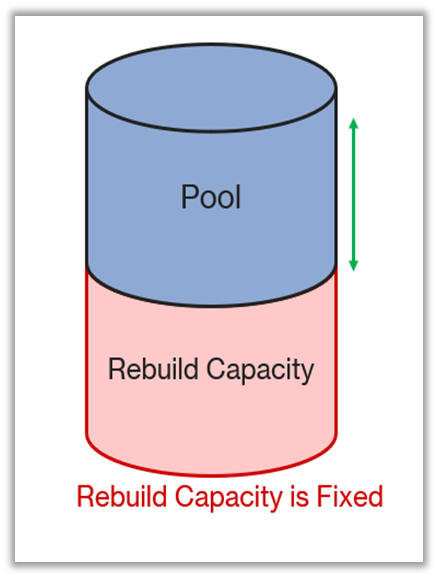
- Fixed(default): A Fixed Rebuild Capacity policy allows you to allocate a fixed disk size exclusively for data rebuild, like a designated spare. You can select a specific number of disks for rebuild capacity.
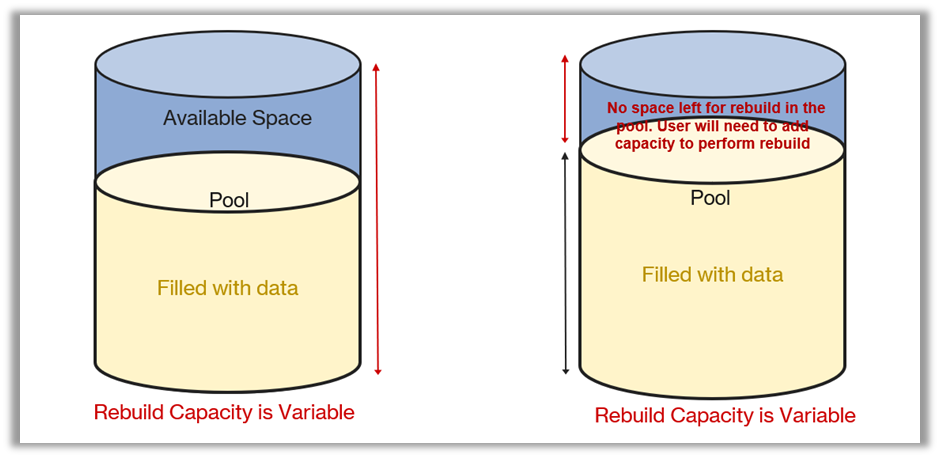
- Variable: A Variable Rebuild Capacity policy enables rebuild capacity only when pool utilization remains low. Rebuild space availability varies based on the free capacity within the pool, that may vary depending on pool utilization.
The following diagram shows how insufficient pool space can limit rebuild capacity, affecting recovery during EBS failures. Rebuild space availability is directly linked to the amount of data within the pool.
How Reserve Rebuild Functions on VSP One SDS Block on AWS
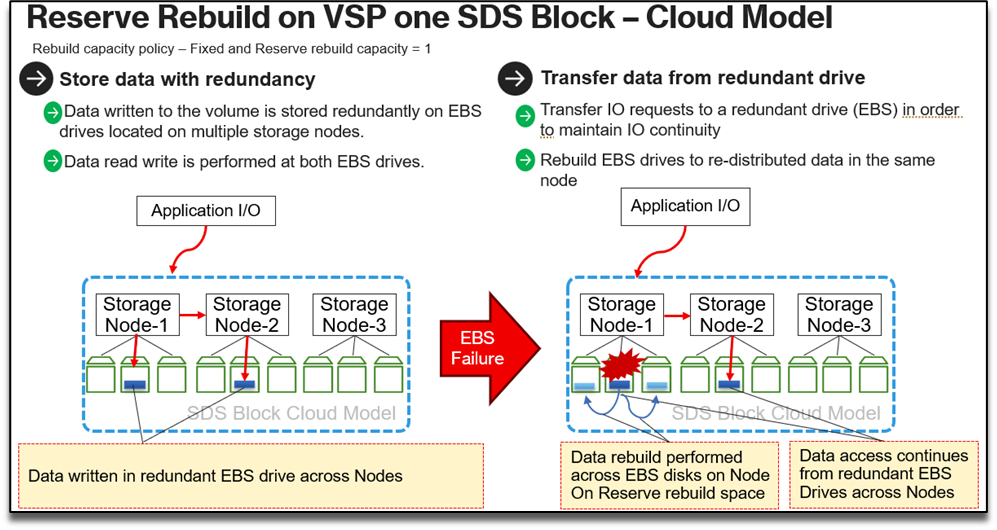
The following diagram shows how the Reserve Rebuild works on the VSP One SDS Block on Cloud, configured with a Fixed Rebuild Capacity policy and a Reserve Rebuild Capacity of one EBS drive per node, ensuring data resiliency within a 3-Node Cluster during EBS drive failures by redundantly storing data across multiple storage nodes and rapidly rebuilding lost data within the affected node using reserved rebuild capacity.
Reserve Rebuild Process:
- Data Redundancy Across Nodes:
● Data is distributed across multiple EBS drives in different storage nodes, such as Node-1, Node-2, and Node-3, to ensure redundancy.
● All drives handle data read/write operations simultaneously, maintaining data availability across nodes.
2. Data Rebuild After EBS Failure:
● During an EBS drive failure, the input/output (I/O) requests redirected to the redundant EBS drives, ensuring operational continuity.
● Data is then rebuilt using the reserved rebuild space, redistributing it within the affected node to restore redundancy.
This process ensures uninterrupted access and rapid recovery by leveraging redundant storage and reserved rebuild capacity after a failure.
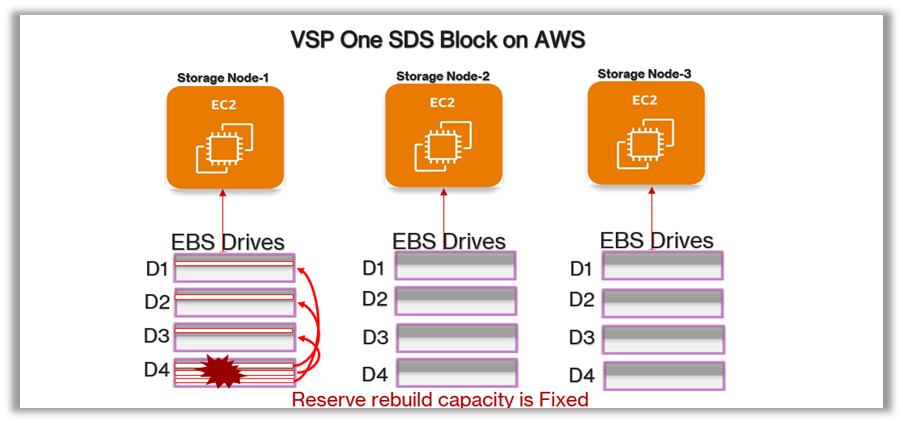
Use Case: EBS Failure with Four Drives per Node and Fixed Reserve Rebuild Capacity of Two
In this scenario, each node includes four EBS drives, with a fixed rebuild policy set to tolerate the failure of up to two drives per node. The configuration reserves an additional space on each drive to ensure sufficient capacity for data rebuilds.

- Single Drive Failure:
● When one EBS drive fails, the remaining three drives allocate 33.3% of their capacity to rebuild data. For example, when D4 fails, D1, D2, and D3 drives allocate 33.3% of their capacity to rebuild data from D4.
● The allocation process restores the data of D4 across the remaining drives while maintaining 66.6% rebuild capacity for future. For example, {100% - (50% + 50%/3 =33.3%)} on each drive, allowing 66.6% of rebuild capacity available.
2. Two Drive Failures:
● When a second drive fails after D4 (e.g., D3), the rebuild capacity is utilized to recover data for both D4 and D3
● 66.6% of D3 space is allocated for rebuild purposes, including 50% of its original data and an additional 16.6% for D4 rebuilt data.
● With a Fixed Rebuild policy for two drives, D1 and D2 are fully allocated to rebuild the data for D3 and D4, using the full reserved capacity across the cluster to maintain data integrity.
This configuration ensures robust data protection by allocating the rebuild capacity across the remaining drives, providing continuity even during two simultaneous drive failures.

Reserve Rebuild Capacity Configuration Options
The configuration options and rebuild outcomes are based on the rebuild capacity policy in a storage system. The rebuild capacity status describes how the storage system manages drive failures per node and the corresponding actions for data restoration. The following table lists the various scenarios based on the number of drive failures and the rebuild capacity status, such as Fixed=1 or Fixed=2.

Using this information, based on the application criticality, you can select between Fixed=1 and Fixed=2 EBS drive rebuild capacities to balance space utilization and resiliency. For high-criticality applications where minimizing downtime is essential, selecting a Fixed=2 rebuild capacity enhances fault tolerance and system resilience by allowing the rebuild of two EBS drives per node during a failure. For less critical applications, Fixed=1 rebuild capacity provides sufficient protection by allowing the rebuild of a single EBS drive per node, with the flexibility to rebuild a second drive if the storage system allows. For example, by adding additional EBS drives to the storage cluster.
Implementation
To configure rebuild capacity based on system requirements, see the Implementation Guide.
Summary
AWS provides a strong uptime guarantee of 99.99%; however, potential downtime of approximately 8.6 seconds per day or over one minute can still risk for I/O interruptions and service disruptions, especially for critical applications. To mitigate these risks, you must implement effective strategies for managing EBS failures and leverage the Reserve Rebuild capabilities of VSP One SDS Block.
Selecting the appropriate rebuild capacity based on application criticality is crucial. Fixed=2 enhances fault tolerance for high-criticality applications, for less critical applications, Fixed=1 provides sufficient protection. Organizations can minimize downtime and maintain robust data protection by aligning rebuild capacity with workload demands.
Additionally, planning for resource expansion when transitioning to Fixed=2 rebuild capacity accommodates increased rebuild requirements, balancing resilience with efficient storage utilization and ensuring high availability during unexpected failures.