Introduction
Firmware upgrades in production environments are often treated with caution—and for good reason. A poorly executed update can lead to downtime, service disruption, or even cluster failure. This becomes even more critical in Azure Local & Windows Hyper-V clusters, where taking down nodes parallelly —even briefly—can bring everything offline.
To solve this, we built a fully automated rolling firmware upgrade framework using Ansible, integrated with ILO tooling like Smart Update Manager (SUM) and iLO REST (ilorest). The goal was simple:
Perform firmware updates without downtime, without manual intervention, and with full control and safety checks.
The Problem with Traditional Firmware Updates
In most environments, firmware updates are:
- Manual and error-prone
- Time-consuming and inconsistent
- Risky in clustered environments
- Lacking proper validation and rollback mechanisms
The Solution: Rolling Firmware Automation
The solution was to implement a rolling upgrade strategy, where:
- Only one node is updated at a time
- Workloads are safely migrated before maintenance
- Each step is validated before moving forward
- The process is fully automated using Ansible
Architecture Overview
At a high level, the solution consists of:
- RHEL Control Node → Runs Ansible and SUM
- Windows / Azure Local Nodes → Managed via WinRM
- iLO Interfaces → Used for firmware deployment and reboot
The control node orchestrates everything, while firmware is applied remotely through iLO.
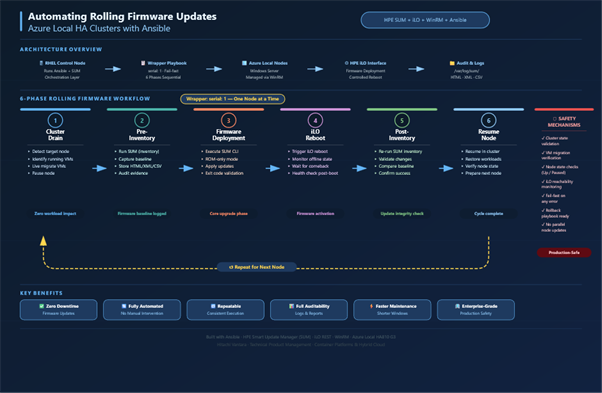
Workflow: Step-by-Step Automation
The automation is divided into 6 structured phases, executed sequentially:
Phase 1 — Cluster Drain
- Detect current node
- Identify running VMs
- Migrate VMs to peer node
- Pause the node for maintenance
Ensures zero workload impact before update
Phase 2 — Pre-Inventory
- Run SUM inventory
- Capture current firmware baseline
- Store logs for comparison
Provides visibility before changes
Phase 3 — Firmware Deployment
- Execute SUM CLI (ROM-only mode)
- Apply applicable firmware updates
- Handle non-applicable components gracefully
Core upgrade phase
Phase 4 — iLO Reboot
- Trigger reboot via iLO
- Monitor iLO going offline and coming back online
- Ensure system stability post reboot
Critical for firmware activation
Phase 5 — Post-Inventory
- Re-run SUM inventory
- Validate firmware changes
- Confirm upgrade success
Ensures update integrity
Phase 6 — Resume Node
- Resume node in cluster
- Restore workload distribution
- Prepare for next node
Completes upgrade cycle
Wrapper Playbook: The Orchestrator
All phases are executed through a wrapper playbook, which:
- Runs phases in sequence
- Uses serial: 1 to process one node at a time
- Stops execution on failure
- Automatically proceeds to the next node
This ensures:
No overlap between nodes
Full control and visibility
Production-safe execution
Built-in Safety Mechanisms
One of the key design goals was production safety. The automation includes:
- Cluster state validation before every phase
- VM migration verification
- Node state checks (Up / Paused)
- iLO reachability monitoring
- Controlled reboot handling
- Fail-fast behavior on errors
This prevents:
Accidental cluster outage
Firmware execution on active nodes
Incomplete upgrade states
Logging and Observability
All operations are logged for traceability:
- SUM logs → /var/log/sum/
- Inventory reports → HTML, XML, CSV formats
- Ansible output → Detailed phase-wise logs
This enables:
- Audit compliance
- Troubleshooting
- Before/after comparison
Key Benefits
· This automation delivers:
· Zero downtime firmware updates
· Fully automated lifecycle
· Reduced operational risk
· Consistent and repeatable execution
· Faster maintenance windows
· Enterprise-grade reliability
Lessons Learned
During implementation, a few key insights stood out:
- Always treat firmware updates like application deployments
- Cluster-aware automation is non-negotiable
- iLO behavior during reboot is not always predictable
- Modular playbooks make troubleshooting much easier
- Logging is your best friend in production automation
Conclusion
Firmware updates no longer need to be stressful, manual, or risky. By combining Ansible with HPE tooling and a well-structured rolling approach, we can transform firmware management into a safe, repeatable, and fully automated process.
This project demonstrates how infrastructure automation, when done right, can significantly improve reliability, reduce downtime, and bring operational maturity to even the most sensitive maintenance activities.
Final Thoughts
If you’re managing clustered infrastructure and still doing firmware updates manually, it’s time to rethink the approach. Automation isn’t just about speed—it’s about consistency, safety, and confidence.