Content Contributor: Bill Schmarzo, Chief Innovation Officer, Hitachi Vantara
There is a phrase in baseball about pitchers “pitching through pain” that refers to pitchers taking the mound to pitch even though they have aches and pains – sore arms, stiff joints, blisters, strained muscles, etc. The idea is that these pitchers are so tough that they can pitch effectively even though they are not quite physically right.
However, when the human system is asked to do something that it’s not prepared to do in the most effective manner, other bad habits emerge in an attempt to counter these aches and pains. One problem is then compounded into multiple problems until the body breaks. Seasons end. And careers die. Sounds like the story of Data Lakes!
Many early data lake projects started with the CIO buying Hadoop, loading lots of data into the Hadoop environment, hiring some data scientists and waiting for magic to happen and waiting for magic to happen.
And now these data lakes are “failing” – and creating data lake “second surgery” situations – for two reasons:
The inability of IT organizations to “move on” on when the original data lake technologies no longer serve their purpose (yes, do not build your data lake on a fax machine).
Beginning the data lake project without deep business context and quantifiable business value in mind.
Forcing a “one size fits all” architecture for all use cases
The Economics of Data Lakes
Economics is about the production, consumption, and transfer of value and the most powerful force in the business world. Let’s see how a basic economic concept, plus one new one, can provide the frame for thinking about how we approach these data lake “second surgeries.”
Our first economics lesson is about the concept of sunk costs. A sunk cost is a cost that has already been incurred and cannot be recovered. Your dad probably referred it as “throwing good money after bad money” (my dad advised me to stop plowing more money into my 1968 Plymouth Fury III). To make intelligent business decisions, organizations should only consider the costs that will change as a result of the decision at hand and ignore sunk costs.
What this means in the world of technology is that once you have bought a particular technology and have trained folks on that technology, those acquisition, implementation and training costs should be ignored when making future decisions.
In the world of Data Lakes (and Data Science), technologies will come and go. So, the sooner you can treat those technology investments as sunk costs, the more effective business decisions you will make. From the “Disposable Technology: A Concept Whose Time Has Come” blog about modern digital companies, we learned two important lessons:
Lesson #1: Focus on aligning the organization on identifying, capturing and operationalizing new sources of customer, product and operational value buried in the company’s data.
Lesson #2: Don’t implement a rigid technology architecture that interferes with Lesson #1.
Solution: Stop factoring what money and time you spent to build your original (failing) data lake as you make new data lake decisions going-forward.
But not understanding sunk costs isn’t the worst economics mistake you can make. Let me introduce you to our second economic concept – Schmarzo’s Economics of Vampire Indecisions Theorem (I’m still campaigning for a Nobel Prize in economics). This principle refers to the inability of organizations to “let go” of out-of-date technologies, and in turn, leads to “Vampire Indecisions”, which is the inability of IT to make the decision to kill irrelevant technologies (e.g., name your favorite data warehouse appliance). Consequently, these technologies continue to linger and slowly drain financial and human resources from more important technology investments.
Heck, Computer Associates has created a business model around organizations that can’t muster the management fortitude to eradicate these irrelevant, outdated technologies.
Solution: Kill…eradicate irrelevant technologies and superfluous data in your data lake to free up human and financial resources to focus on those technologies and data sources that support the organization’s business strategy.
Creating New Sources of Economic Value
However, the biggest problem driving most data lake “failures” is the inability to leverage the data in the data lake to derive and drive data monetization efforts; that is, to uncover new sources of customer, product and operational value.
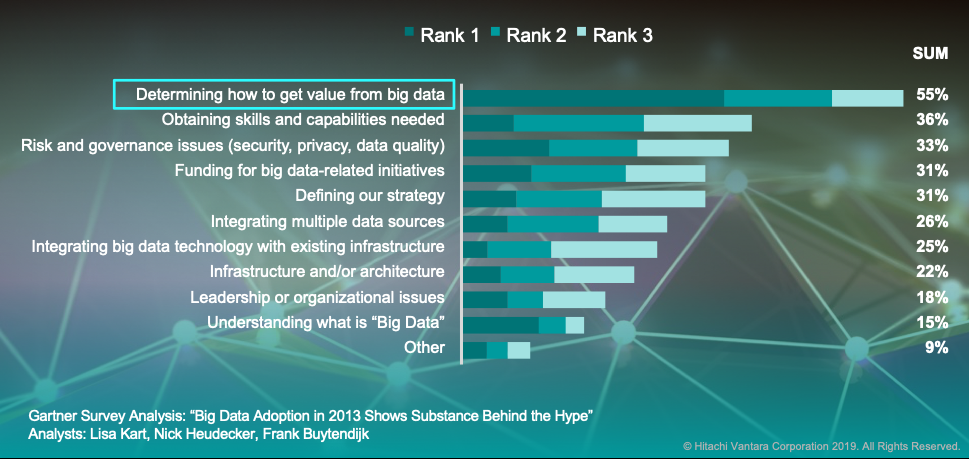
CIO's Top Challenges
If one does not know what business value they are trying to derive and drive out of their data lake (what is the targeted use case, what are the metrics against which progress and success will be measured, what decisions does that use case need to support, etc.), then the organization doesn’t know what data sources are critical and which ones are not. Consequently, the IT organization defaults to loading lots of unnecessary data into the data lake resulting in a swamp of uncurated, unusable-to-the-business-user data.
However, once the high-priority data sources are identified, then IT organizations can embrace DataOps to turn that data swamp into a data monetization goldmine. DataOps is the key to driving the productivity and effectiveness of your data monetization efforts. It enables your data science team to explore variables and metrics that might be better predictors of performance, and not be burdened with the data aggregation, cleansing, integration, alignment, preparation, curation and publication processes. The figure below shares details on the symbiotic role of DataOps and Data Science to drive Data Monetization.
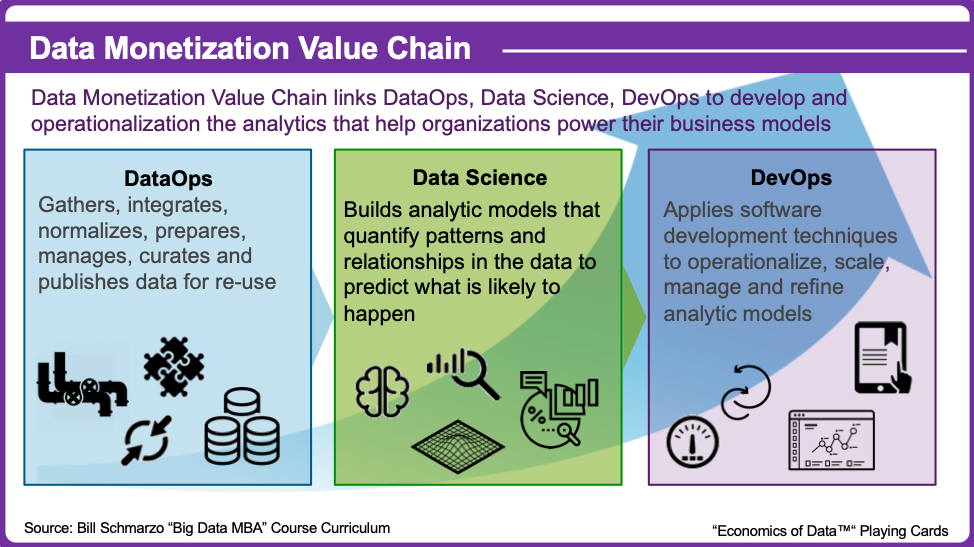
Data Monetization Value Chain
Data Lake “Second Surgery”: Hitachi Vantara Learnings
Yes, Hitachi Vantara has lived this Data Lake story – buying Hadoop, loading lots of data into the Hadoop environment, hiring some data scientists and waiting for magic to happen. However, the difference between the Hitachi Vantara story and other failed data lakes is that we started the data lake “second surgery” by re-setting the data lake technology platform, identifying a business partner with whom to collaborate around the creation of business value and embracing our Data Science Digital Value Enablement (DVE) process.
The effort endeavored upon:
- Ran a DVE Vision Workshop to identify, validate, value and prioritize the use cases, while building Marketing, Finance, Operations, Sales and IT alignment – where a data lake could provide the foundation for a data science engagement.
- Took the top priority use case (New Product Introduction Targeting) and ran it through our DVE Proof of Value methodology (think lots of data engineering and data science work).
- Developed, tested and validated three analytic models (propensity to buy score, customer engagement recommendation engine, and survival model) using a proxy new product introduction.
- Integrated these scores into sales, product and support systems so that Hitachi Vantara is focusing support on those customers who can benefit the most from our new product, as well as the reasons why (based upon customer usage models and service history).
But, here’s my observation – we were able to achieve 90% model predictive accuracy using only 3 data sources! Yes, just three! The importance of this learning is that organizations don’t need to start the process by loading tens if not hundreds of data sets into the data lake. If the organization has a deep understanding of the problem they are solving, the efficiency and effectiveness gained in initially limiting the data to work with, enables focus on the data cleansing, completeness and enrichment activities of those 3 most important data sets.
Now, can we further engineer those 3 data sources to improve model accuracy? Definitely, and that’s where IT will be focusing much of their data improvement efforts.
However, here’s the real interesting question: could we improve model accuracy by incorporating more data sources? Possibly, but at some point, the costs of investigating new data sources has to be weighed against the marginal value in the improvements in the analytic model. That is, it is an economic decision whether to continue to invest resources in improving this model and the supporting data or reassign that investment to the next use case (we have at least 10 more for Marketing).
Summary
The Data Lake can become a “collaborative value creation platform” that drives organization alignment around identifying and prioritizing those use cases that can derive and drive new sources of customer, product and operational value. However, don’t “pitch through pain” with a technology platform and a monetization approach that are outdated. Embrace the economic concepts associated with Sunk Costs and Vampire Indecisions to “let go” and move forward, especially as Data Lake “second surgeries” become the norm.
Key blog points:
- Much like how a professional athlete “playing through pain” can lead to the development of bad habits that limit effectiveness and end careers, IT systems can experience the same syndrome when bad habits are developed to overcome the inherent problems in poorly architected systems.
- In the world of data lakes, we see many IT organizations trying to “play through the pain” of a poorly constructed and targeted data lakes. The result: data lake “second surgery” situations that can kill CIO careers.
- The data lake “second surgery” solution starts with an understanding of some basic economics concept – Sunk Costs and Vampire Indecisions.
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------
#ThoughtLeadership#Blog